从单机到分布式 数据处理演进与核心技术详解

数据处理是信息时代的核心引擎,随着数据量的爆炸式增长,其实现方式也在不断演进。本文将系统性地梳理从单机数据处理到集群与分布式计算的完整技术栈,并深入解析Spark、多任务处理以及支撑服务等关键概念。
一、数据处理的基本范式:单机与集群
单机数据处理是最传统和基础的模式,即所有计算任务和数据都集中在一台物理或虚拟计算机上完成。其优势在于架构简单、部署容易、无需复杂的协调机制,适用于数据量较小、计算复杂度不高的场景,例如个人数据分析、小型企业报表生成等。常见的单机工具包括Excel、Access、甚至利用Python的Pandas库进行数据分析。单机模式受限于单台机器的计算能力(CPU、内存、I/O)和存储容量,难以应对TB/PB级大数据和复杂的实时计算需求。
集群数据处理是为了突破单机瓶颈而生的解决方案。它将多台计算机(称为节点)通过网络连接起来,形成一个统一的资源池,共同完成任务。集群的核心思想是“分工协作”,通过将大规模任务分解并分发到多个节点并行执行,从而显著提升整体处理能力和可靠性。根据协作方式的不同,集群处理可分为两类:
1. 高性能计算集群:侧重于通过并行计算加速单个复杂任务,如科学模拟。
2. 负载均衡集群:将大量并发任务(如网页请求)分发到不同节点,以提高吞吐量。
集群数据处理为大数据处理奠定了基础,但其早期的实现往往需要开发者手动管理数据分片、任务调度和节点通信,复杂度较高。
二、分布式计算框架:自动化与抽象化
为了简化集群数据编程的复杂性,分布式计算框架应运而生。它提供了高级别的编程抽象和自动化的资源管理,使开发者能够像编写单机程序一样处理分布在集群上的海量数据,而无需深陷网络通信、故障恢复等底层细节。
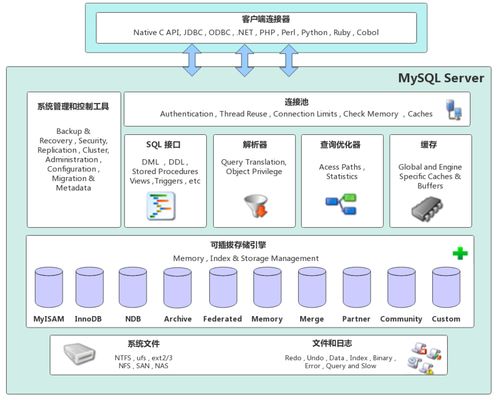
Apache Spark 是当前最主流的分布式计算框架之一。它与早期MapReduce框架相比,核心突破在于其内存计算模型。Spark将中间计算结果尽可能保存在内存中,而非像MapReduce那样频繁读写磁盘,这使得它在处理迭代算法(如机器学习)和交互式查询时,性能可提升数十倍乃至百倍。
Spark的分布式计算核心概念包括:
- 弹性分布式数据集(RDD):是不可变的、分区的数据集合,是Spark的基本数据抽象。它记录了数据的谱系(Lineage),能够在节点故障时自动重建,提供了容错性。
- 有向无环图(DAG):Spark将用户程序转换成一系列由RDD转换和动作构成的DAG,并由DAG调度器进行优化和分阶段(Stage)执行,提升了执行效率。
- 统一栈:Spark提供了Spark SQL(结构化数据处理)、Spark Streaming(流处理)、MLlib(机器学习)、GraphX(图计算)等高层库,形成了一个统一的、功能强大的数据处理生态系统。
三、并行计算的基石:多任务、进程与线程
无论是在单机还是分布式环境中,并发与并行都是提升处理能力的关键。理解其底层机制至关重要。
- 多任务:指操作系统同时运行多个程序的能力。这是宏观概念,由操作系统内核的调度器实现。
- 进程与线程的区别:
- 进程:是资源分配的基本单位。每个进程都有独立的地址空间(内存)、数据栈、文件描述符等系统资源。进程间通信(IPC)成本较高,需要借助管道、消息队列、共享内存等机制。
- 线程:是CPU调度的基本单位,是进程内的一个执行流。同一进程内的所有线程共享该进程的绝大部分资源(如内存空间、打开的文件),主要拥有自己独立的栈空间和程序计数器。线程间通信和切换成本远低于进程。
在分布式计算框架如Spark中,一个任务(Task)通常在一个线程中执行。Spark的Executor进程在集群节点上启动,每个Executor内会运行多个线程来并发执行多个Task,从而实现高效的并行计算。
四、数据处理与存储的支撑服务
一个完整的大数据体系,除了计算框架,还离不开一系列支撑服务的协同。
- 数据存储服务:
- 分布式文件系统:如HDFS、S3,提供高吞吐量、高可靠的海量文件存储,是数据湖的基石。
- 分布式数据库/数据仓库:如HBase(NoSQL)、ClickHouse(OLAP)、Snowflake(云数仓),为特定查询模式提供高效的数据组织和访问能力。
- 资源管理与调度服务:
- 如YARN、Kubernetes,负责集群中CPU、内存等资源的统一管理和分配,为Spark等计算框架提供运行容器,实现多租户、多应用共享集群资源。
- 数据协调与服务发现:
- 如ZooKeeper、etcd,在分布式系统中提供可靠的配置维护、命名服务、分布式同步和组服务,保障集群的元数据一致性和协调工作。
- 数据集成与流处理服务:
- 如Apache Kafka(消息队列)、Flink(流计算框架),负责实时数据流的采集、传输和处理,构成实时数据管道。
###
数据处理方式的演进,是一条从集中到分散、从手动到自动、从单一到生态的路径。单机处理是原点,集群提供了物理基础,而像Spark这样的分布式计算框架则通过高级抽象释放了集群的潜力。深刻理解进程、线程等并发模型是优化程序性能的关键。所有这些组件与存储、调度、协调等支撑服务共同构成了一个健壮、高效、可扩展的现代大数据处理平台,驱动着各行各业的数字化转型与智能决策。
如若转载,请注明出处:http://www.xingfuqhd.com/product/32.html
更新时间:2026-06-19 02:25:39